

CodeRabbit is the industry's most advanced AI code reviewer with thousands of customers and used by over 100,000 open-source projects. Its unique context engineering approach designed specifically for code reviews helps catch difficult to find bugs, refactor code, identify edge cases, and improve overall code quality.
While other code review tools merely skim the surface looking for simple bugs, CodeRabbit ingests critical context from multiple data sources intelligently: past PRs, Jira/Linear tickets to reveal developer intent, code graph analysis, custom instructions for personalization of reviews, and chat based learnings from users. The result? Reviews with human-like precision that reduce PR merge time and bugs in half.
At the core of CodeRabbit's tech stack lies LanceDB, the vector database that transforms chaotic context into real-time architectural insight. While other solutions buckle under scale, LanceDB delivers millisecond semantic searches across CodeRabbit's living knowledge graph: dynamically querying tens of thousands of tables (PRs, issues, code dependencies, tribal learnings) indexing millions of daily code interactions.
“LanceDB transformed how we handle context at scale. While other vector databases hit cost and performance walls, LanceDB scales effortlessly with our growth—from startup to enterprise. Its multimodal capabilities and deployment flexibility were game-changers, enabling us to deliver the depth of analysis our customers expect while maintaining sub-second response times across millions of code reviews.”
— Rohit Khanna, VP of Engineering at CodeRabbit
This is the contextual understanding that is critical for modern, complex codebases. Designed for enterprise customers, LanceDB supports cloud and on-prem deployments with secure, low-latency performance. As CodeRabbit's customer base exploded, LanceDB scaled effortlessly, preserving speed while avoiding spiraling infrastructure costs.
The result: every pull request improves code quality, while LanceDB handles the complexity behind the scenes.
Introduction: CodeRabbit - defining the future of AI-powered code reviews
In the AI coding era where the pace of software generation is far more than human review capacity, CodeRabbit has emerged as the category leader in AI-powered code reviews. Trusted by engineering teams across industries to deliver speed, precision, and scale. Purpose-built for modern development, CodeRabbit doesn't just assist with reviews, it transforms them into a competitive advantage.
Today, CodeRabbit performs tens of thousands of code reviews every day, proving its ability to support enterprise-scale workflows without compromising quality. Its seamless integration with IDEs like VS Code, Cursor, and Windsurf with its lightweight extension has fueled widespread adoption, from fast-moving startups to some of the world's most demanding companies. By delivering reviews that are fast, context-aware, secure, and remarkably accurate, CodeRabbit is defining how developers impose guardrails on AI generated code.
CodeRabbit impact:
- Massive Throughput: Processes millions of pull requests monthly, proving enterprise-grade reliability and scale.
- Productivity Gains: Customers report 50%+ reduction in manual review effort, with some teams achieving 80%+ faster development cycles.
- Fewer Issues: AI-powered context analysis reduces code issues by up to 50% when compared with manual code reviews
- Flexible Integration: Instantly usable across leading Git platforms and code editors, delivering real-time feedback without disrupting developer flow.
Challenge: context-aware code reviews at scale
For CodeRabbit to deliver AI code reviews at the level of a senior developer, it must construct meaningful context from fragmented signals across massive and evolving codebases. Unlike static linting tools, effective AI review requires connecting the dots across code changes, architectural patterns, historical decisions, and team conventions, all in real time.
This challenge unfolds across three layers:
1. Code Layer – review beyond the diff
Most pull requests appear self-contained, but reviewing them requires understanding changes across files, modules, and dependency chains. Understanding the actual impact means going beyond the diff:
- The "Grep Trap": regex and rule-based tools fall short when semantics matter—like tracing all authentication logic linked to `userAuth()`, even when naming or patterns vary across services.
- Code relationships: finding relevant code to what was updated in the PR.
2. Project Layer – keep up with changing architecture
Today’s codebases are constantly evolving with new architectural decisions coming in place. Understanding change impact means capturing cross-repository relationships and historical design intent:
- Dependency graph limitations: static analysis often misses runtime and dynamic behavior, or architectural coupling between microservices.
- Historical blind spots: critical context, such as why a fix was made, often lives in old PRs, Jira tickets, or Slack threads. These signals are valuable but scattered.
3. Human Layer – intent, convention, and tribal knowledge
Even perfect syntax and architecture can violate design intent. Great reviews demand cultural awareness:
- Tribal knowledge gap: Teams follow unspoken rules—like “input validation always lives in lib/security”—that aren’t enforced by compilers or captured in documentation.
- Architectural drift: A "simple" refactor might unintentionally break invisible service boundaries or violate implicit contracts.
And Then, Volatility
Context is high-dimensional, unstructured, and constantly evolving. Every new commit, comment, and design decision reshapes what matters.
“Retrieving the right context is like finding needles in a million haystacks… while the haystacks are constantly reshaping themselves.”
Why semantic search wasn’t enough
There’s no question that building this kind of context demands deep semantic intelligence. CodeRabbit initially adopted a popular closed-source database to enable vector-based similarity search across its knowledge graph. It was a step in the right direction, but only part of the solution:
- Cost at scale: As usage expanded to millions of pull requests and tens of thousands of daily queries, their pricing model became unsustainable. Real-time retrieval over massive repositories incurred runaway costs, especially when processing large amounts of text.
- Deployment constraints: The existing product offered no viable path for true on-premises deployment. For CodeRabbit’s enterprise customers, many operating in regulated or air-gapped environments, this was a dealbreaker. They required strict data residency guarantees and full infrastructure control.
Why LanceDB became the only solution that worked
Scaling semantic context retrieval in real-world environments meant looking for other alternatives. CodeRabbit needed a vector database designed not for theoretical benchmarks, but for the messy, high-velocity realities of software engineering.
| Task | CodeRabbit Requirements |
|---|---|
| Semantic search at scale | Retrieve relevant context for 50K+ daily PRs with P99 latency under 1 second |
| Metadata filtering | Combine embeddings with filters (e.g., "Go files on auth modified after Jan 2024") |
| Dynamic indexing | Ingest and optimize new context types on the fly |
| High velocity upserts | Continuously handle new commits, no downtime, no re-indexing |
| Infrastructure agnostic | Seamless cloud + on-prem deployment to meet strict enterprise security and data residency needs |
| Cost-effective | Sustain performance even as traffic scales 100x, without runaway costs |
Enter LanceDB: Purpose-Built for Real-World AI Scaling
LanceDB solved CodeRabbit's challenges decisively, unlocking a new level of performance, security, and efficiency:
- Cost efficiency: with its optimized compute and storage design, LanceDB maintains sub-second latency and stable costs, even as usage scales 100x.
- On-Prem deployments: a single lightweight binary deploys in secure, air-gapped environments in minutes—no infrastructure rework, no code changes required.
Results: CodeRabbit now delivers real-time, architecture-aware code reviews at enterprise scale, without sacrificing performance, security, or cost. With LanceDB at its core, CodeRabbit reviews every pull request and becomes a centralized software quality guardrail.
Solution: LanceDB as the context engine behind CodeRabbit
To solve the complexity of real-time, context-aware code review, CodeRabbit built a sophisticated context engineering pipeline powered by LanceDB, a vector database purpose-built for semantic retrieval at scale. LanceDB enables CodeRabbit to ingest, embed, and retrieve high-dimensional knowledge across fragmented sources, serving as the brain behind its AI review engine.
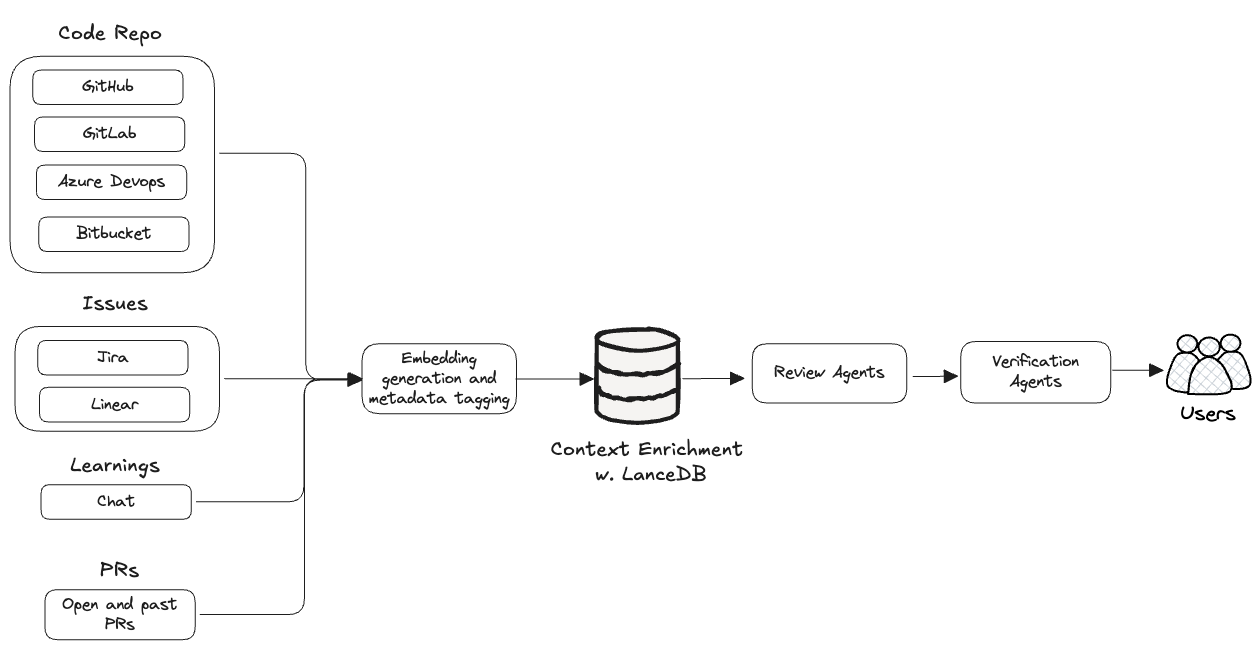
Engineering with LanceDB
At the heart of CodeRabbit's architecture is its Context Engineering approach, which continuously synthesizes code, known issues, and review instructions stored and queried through LanceDB. This system empowers CodeRabbit to surface relevant, project-specific insights in milliseconds for every code review. More details on how CodeRabbit works behind the scenes can be found in their engineering blog.
Multi-source data ingestion
LanceDB ingests and indexes data from diverse sources:
- Code structure: captures both syntactic and semantic structure.
- Issue trackers: Jira and Linear tickets provide intent and problem context.
- Historical reviews: Past pull requests and decisions enable pattern recognition
Real-time retrieval & dynamic Context Assembly
When a pull request is opened, LanceDB powers a real-time context retrieval pipeline:
- Embedding generation: newly pushed code is parsed and embedded
- Semantic lookup: LanceDB retrieves all information relevant to the review
LLM-orchestrated review, powered by Vector Search
The retrieved context drives CodeRabbit’s LLM review engine, enabling precise and actionable feedback:
- LanceDB-sourced results feed into task-specific LLMs.
- Similar past reviews and fixes improve future LLM comments
- Details from linked issues ensure that reviews are aligned with goals
Always-on learning loop
LanceDB continuously evolves as CodeRabbit learns from new data:
- Live feedback integration: developer chats and PR outcomes are re-embedded
- Auto-updating vectors: updates are triggered automatically without manual reindexing.
- Pattern drift detection: As team behaviors evolve, the vector index adapts automatically.
By integrating LanceDB as the backbone of its context engine, CodeRabbit transforms fragmented engineering signals into actionable intelligence, powering real-time, architecture-aware code reviews that scale with confidence.
“LanceDB was the only vectordb that fit our unique usecase - scaled to a large number of customers with massive tables and supported running on various custom environments. This helped us land more customers, and grow faster.”
- Ganesh Patro, software engineer at CodeRabbit
Summary
LanceDB has become the semantic engine behind CodeRabbit’s evolution into a category-defining AI code review platform, unlocking both massive scale and precision that was previously unattainable. LanceDB has empowered CodeRabbit to deliver:
- Sub-second latency for semantic search across millions of code interactions
- Millions of pull requests processed monthly: LanceDB’s optimized upsert and indexing pipeline ensures real-time ingestion without any performance degradation
- Effortless on-prem and cloud deployment: LanceDB enables CodeRabbit to run securely in both air-gapped enterprise and cloud environments without code changes or operational overhead
Looking ahead, CodeRabbit is setting its sights on redefining the future of AI-native engineering. The team is expanding its context graph to encompass even richer signals, runtime traces, architectural diagrams, CI/CD events, and more, creating a living blueprint of every system it touches.
With deeper integrations into planning tools and observability stacks, CodeRabbit aims to not just review code, but act as a centralized governance layer identifying risks and guiding developers with insights drawn from millions of engineering years worth of built-in intelligence.



