
Vector databases often come with an unwelcome surprise.
Once your RAG or Agentic prototype turns to production traffic, the storage and retrieval bill can spike faster than you can say “token limit.”
Vector search engines such as LanceDB , Turbopuffer, Chroma, or S3 Vectors offer a common solution: store your vectors in S3, pay pennies for storage, and only get charged per query.
This method of storage has become a huge reprieve for petabyte-scale GenAI startups, such as Cursor (Turbopuffer) or Harvey and Midjourney (both on LanceDB).
The Promise of S3 Vectors
Amazon S3 Vectors introduces a new class of S3 bucket—a vector index natively embedded into S3 itself. You upload embeddings, attach optional metadata, and query for similarity matches.
The appeal is clear. S3 storage is inexpensive and centralized. AWS S3 Vectors, in particular, is an even better proposition. It is vector-native and indexes on your behalf.
Figure 1: AWS S3 Vectors integrates with Bedrock, Sagemaker, Athena & OpenSearch, so you can build a full retrieval-augmented generation workflow without leaving AWS.
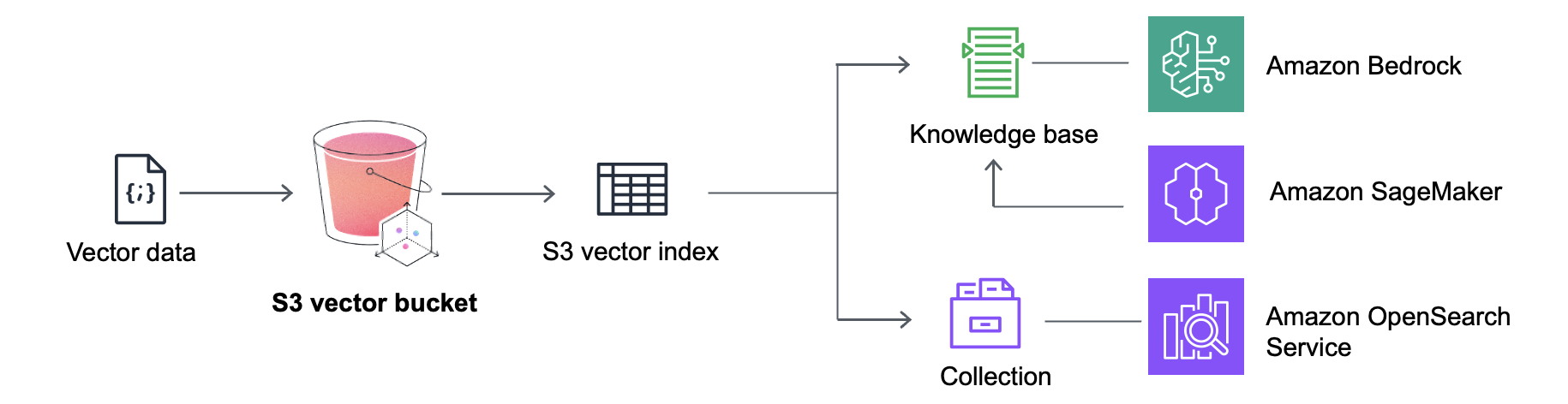
Need more than GenAI? If you’re into analytics and need a lakehouse - you’ll need to integrate with additional AWS services, such as S3 Tables, for structured data analytics.
Wait…Isn’t This Just LanceDB?
Thanks for asking, Jim!
S3 Vectors is a black box, but we don’t think so - because our open-source LanceDB product is pretty much the entire AWS stack combined!
LanceDB is multimodal. This means that it has Tables and Vectors built into the same storage system. This is something that’s been increasingly important for companies looking to do analytics, training and feature engineering.
AWS Athena? Our Enterprise product has SQL built in. Need embeddings? We’ve got the API. OpenSearch? You get the idea.
We agree…the Multimodal Lakehouse is another way users can harness the power of Lance format , which makes structured and unstructured data both first-class citizens.
But let’s get to the focus of S3 Vectors - GenAI Builders.
The Complexity of AWS Microservices
Each AWS service introduces its own configuration, IAM policies, and fees. Setting up and maintaining these connections can take as much time as tuning queries.
Let’s take a look at a typical RAG workflow with all the AWS services:
[Input Text]
|
[Embed via Bedrock] -------------------------
| |
[S3 Vectors] (for similarity) [Additional AWS Services] (for structured data)
| |
[OpenSearch] (optional for latency) |
| |
-------------> [LLM via Bedrock] <------That’s 5+ services, each with its own cost, IAM model, SDK/API, and data governance requirements. The AWS announcement is very carefully written to stay ambiguous performance-wise.
The real trade-off isn’t just complexity—it’s data architecture. S3 Vectors requires you to export and duplicate your data across multiple services, creating data silos that contradict the lakehouse philosophy of unified data access.
When you need both vector search and structured analytics, you’re forced to maintain separate data copies across multiple AWS services, each with their own indexing and governance models.
The Delivery of LanceDB
Let’s look at LanceDB in a typical RAG stack:
[Input Text]
|
[LanceDB on S3] + [Embedding]/[Indexing]/[Search]/[Reranking]
|
[LLM via anything] Figure 2: Retrieval Augmented Generation (RAG) with LanceDB

LanceDB takes a streamlined path. Instead of mixing several services, you use a single embedded, open-source library. Indexing, search, analytics, and lakehouse-style table support are included (everything except the LLM itself). There are no additional services to monitor, and there is no vendor lock-in.
Whether you run it in a notebook, a serverless function, or on-premise hardware, it behaves consistently.
While S3 Vectors promises native scale and integration within the AWS ecosystem, LanceDB takes a fundamentally different approach: unified storage for all data types, advanced search APIs, and deep alignment with ML developer workflows.
We believe this simplicity is a significant advantage in enterprise GenAI. Combined with the fact that LanceDB can be hosted on-prem in completely custom environments , we offer the flexibility and control enterprises need to meet strict security, compliance, and performance requirements.
The Hidden Trade-offs for GenAI Builders
The complexity of S3 Vectors goes beyond just managing multiple services. Here are the key challenges GenAI builders face when building retrieval systems:
| Challenge | S3 Vectors + OpenSearch | LanceDB |
|---|---|---|
| Data Freshness vs Performance | Point-in-time export creates tension: stale but “performant” data vs fresh but slow | Real-time queries with consistent performance |
| Vector Search Performance | OpenSearch limitations for sub-second latency | Optimized for fast RAG applications |
| Format Consistency | Two different systems (S3 Vectors + OpenSearch) with different APIs | Single Lance format across all deployments |
| Data Portability | Proprietary formats create vendor lock-in | Open Lance format ensures data portability |
| Multimodal Support | Requires multiple AWS services (S3, S3 Tables, S3 Vectors) | Unified system handles all data types |
Key Questions for GenAI Builders
When choosing between S3 Vectors and LanceDB, consider these critical factors:
Team & Integration
- How much integration work can your team support? If your organization already relies heavily on AWS, S3 Vector may feel natural, but every new integration adds configuration files to maintain. LanceDB arrives pre-configured , offering less flexibility in exchange for reduced setup effort.
Performance & Latency
- What’s your latency requirement? If you need sub-100ms response times for real-time RAG applications, the performance gap between OpenSearch and LanceDB becomes critical. S3 Vectors with OpenSearch export creates a performance vs. freshness trade-off that LanceDB eliminates.
Data Architecture
-
Do you require lakehouse-grade analytics? S3 Vector focuses on storage. If you need ACID tables, versioned datasets, or fast aggregate queries, you must add another service. LanceDB provides these functions natively , letting your BI dashboards and ML pipelines rely on one engine.
-
Do you need multimodal data? If you’re working with images, videos, features, and vectors together, S3 Vectors forces you into multiple AWS services. LanceDB’s unified approach means one system handles all your data types without format fragmentation.
Future-Proofing
- How important is vendor lock-in? S3 Vectors and OpenSearch are proprietary formats. LanceDB’s open Lance format means your data is portable and future-proof, regardless of where you choose to run it.
Final Thoughts
S3 Vectors is a strong choice for AWS-native workloads, especially when your data already lives in S3 and you need scalable governance, multi-tenant controls, or integrations with Bedrock and Lake Formation.
But for 90% of developers building RAG systems, AI agents, or embedded search features, LanceDB is the simpler, faster, and more productive choice. It gives you vector search, structured filtering, and local iteration—without needing five cloud services or a DevOps team.




