
Chunking Techniques with Langchain and LlamaIndex
In our last blog, we talked about chunking and why it is necessary for processing data through LLMs. We covered some simple techniques to perform text chunking.
In our last blog, we talked about chunking and why it is necessary for processing data through LLMs. We covered some simple techniques to perform text chunking.

Explore lance v2: a new columnar container format with practical insights and expert guidance from the LanceDB team.

In our article, we explored the remarkable capabilities of the Lance format, a modern, columnar data storage solution designed to revolutionize the way we work with large image datasets in machine learning.

Working with large image datasets in machine learning can be challenging, often requiring significant computational resources and efficient data-handling techniques.

Explore a practical guide to fine-tuning embedding models with practical insights and expert guidance from the LanceDB team.

Streaming data applications can be tricky. When you can read data faster than you can process the data then bad things tend to happen. The various solutions to this problem are largely classified as backpressure.

Explore designing a table format for ML workloads with practical insights and expert guidance from the LanceDB team.

Explore GraphRAG: hierarchical approach to retrieval-augmented-generation with practical insights and expert guidance from the LanceDB team.
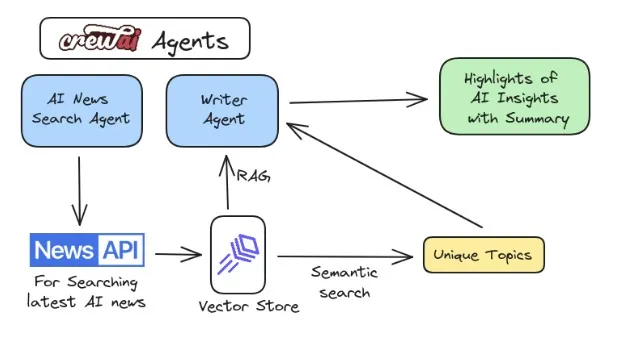
This article will teach us how to make an AI Trends Searcher using CrewAI Agents and their Tasks. But before diving into that, let's first understand what CrewAI is and how we can use it for these applications.