Prerequisites
- Kubernetes cluster with KubeRay 1.1+ operator installed
- Ray 2.43+
See below for installation instructions for:
- Amazon Web Services (AWS) Elastic Kubernetes Service (EKS)
- Google Cloud Platform (GCP) Google Kubernetes Engine (GKE)
Basic Kubernetes Setup
In the following sections we’ll use these variables:
NAMESPACE=geneva # replace with your actual namespace if different
KSA_NAME=geneva-ray-runner # replace with an identity nameKubernetes Service Account (KSA)
Inside your Kubernetes cluster, you need a Kubernetes service account which provides the credentials your k8s pods (Ray) run with. Here’s how to create your KSA.
Create a Kubernetes Service Account (KSA)
kubectl create namespace $NAMESPACE # skip if it already exists
kubectl create serviceaccount $KSA_NAME \
--namespace $NAMESPACEYou can verify using:
kubectl get serviceaccounts -n $NAMESPACE $KSA_NAMEThe Kubernetes service account (KSA) needs RBAC permissions inside the k8s cluster to provision Ray clusters via CRDs.
Create a k8s Role
Create a k8s role that can access the Ray CRD operations.
kubectl apply -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: ${KSA_NAME}-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
- apiGroups: ["ray.io"]
resources: ["rayclusters"]
verbs: ["get", "patch", "delete"]
EOFBind the ClusterRole to Your KSA
kubectl apply -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: ${KSA_NAME}-binding
subjects:
- kind: ServiceAccount
name: ${KSA_NAME}
namespace: ${NAMESPACE}
roleRef:
kind: ClusterRole
name: ${KSA_NAME}-role
apiGroup: rbac.authorization.k8s.io
EOFNow confirm your permissions:
kubectl auth can-i get pods --as=system:serviceaccount:${NAMESPACE}:${KSA_NAME}Geneva on GKE
Google Kubernetes Engine (GKE) is a GCP service that deploys Kubernetes and can manage on-demand provisioning of cluster nodes. Ray can be deployed on GKE clusters using the KubeRay k8s operator.
GKE provides the option for an out-of-the-box KubeRay operator deployment. The version of KubeRay is tied to the version of GKE you have deployed. Currently these versions are supported:
- GKE 1.30 / KubeRay 1.1
- GKE 1.31 / KubeRay 1.2
Alternatively, you can also deploy your own KubeRay operator to get the latest KubeRay 1.3 version.
The following sections describe in more details other required configuration settings required for Geneva to perform distributed execution.
GKE Node Pools
GKE allows you to specify templates for virtual machines in “node pools”. These allow you to manage and configure resources such as the number of CPUs, number of GPUs, amount of memory, and if instances are spot or regular virtual machines.
You can define your node pools however you want but Geneva uses three specific Kubernetes labels when deploying Ray pods on GKE: ray-head, ray-worker-cpu, ray-worker-gpu
-
Head nodes are where the Ray dashboard and scheduler run. They should be non-spot instances and should not have processing workloads scheduled on them. Geneva looks for nodes with the
geneva.lancedb.com/ray-headk8s label for this role. -
CPU Worker nodes are where distributed processing that does not require GPU should be scheduled. Geneva looks for nodes with the
geneva.lancedb.com/ray-worker-cpuk8s label when these nodes are requested. -
GPU Worker nodes are where distributed processing that require GPU should be scheduled. Geneva looks for nodes with the
geneva.lancedb.com/ray-worker-gpuk8s label when these nodes are requested.
GKE + k8s Permissions
Geneva needs the ability to deploy a KubeRay cluster and submit jobs to Ray. The workers in the Ray cluster need the ability to read and write to the Google Cloud Storage (GCS) buckets. This requires setting up the proper k8s permissions and GCP IAM grants. There are three main areas to setup and verify:
- Kubernetes Service Account (KSA)
- Google Service Account (GSA)
- GKE settings (GKE workload identity)
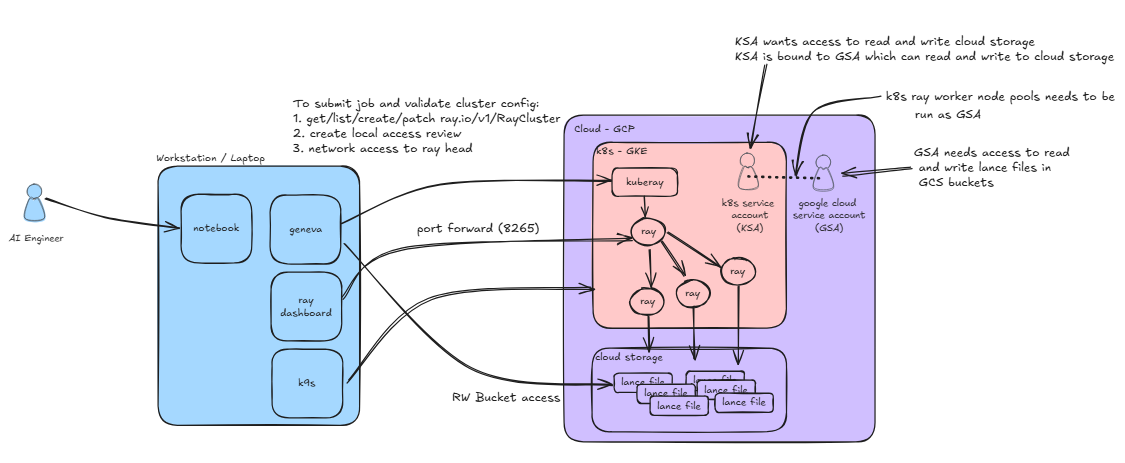
Geneva Security Requirements
In the following sections we’ll use these variables:
NAMESPACE=geneva # replace with your actual namespace if different
KSA_NAME=geneva-ray-runner # replace with an identity name
PROJECT_ID=... # replace with your google cloud project name
GSA_EMAIL=${KSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
LANCEDB_URI=gs://bucket/db # replace with your own pathGoogle Service Account (GSA)
To give your k8s workers the ability to read and write from your LanceDB buckets, your KSA needs to be bound to a Google Cloud service account (GSA) with those grants. With this setup, any pod using the KSA will automatically get a token that lets it impersonate the GSA.
Let’s set this up:
Create a Google Cloud Service Account
gcloud iam service-accounts create ${KSA_NAME} \
--project=${PROJECT_ID} \
--description="Service account for ray workloads in GKE" \
--display-name="Ray Runner GSA"You can verify this using:
gcloud iam service-accounts list --filter="displayName:Ray Runner GSA"Warning: You need
roles/iam.serviceAccountAdminor minimallyroles/iam.serviceAccountTokenCreatorrights to run these commands.
Next, you’ll need to verify that your KSA is bound to your GSA and has roles/iam.workloadIdentityUser:
gcloud iam service-accounts get-iam-policy $GSA_EMAIL \
--project=$PROJECT_ID \
--format="json" | jq '.bindings[] | select(.role=="roles/iam.workloadIdentityUser")'Give your GSA rights to access the LanceDB bucket:
gcloud storage buckets add-iam-policy-binding ${LANCEDB_URI} \
--member="serviceAccount:${KSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/storage.objectAdmin"GKE Workload Identity
A GKE workload identity is required to enable k8s workloads access Google Cloud services securely and without needing to manually manage service account keys. The workload identity is attached to Google Cloud service accounts (GSA) and mapped to a Kubernetes service account (KSA). This feature needs to be enabled on the GKE cluster.
You can confirm that your workers have abilities to read/write to the LanceDB bucket:
kubectl run gcs-test --rm -it --image=google/cloud-sdk:slim \
--serviceaccount=${KSA_NAME} \
-n ${NAMESPACE} \
-- bash
echo "hello" > test.txt
gsutil cp test.txt ${LANCEDB_URI}/demo-check/test-write.txtConfirm the identity inside the pod:
curl -H "Metadata-Flavor: Google" \
http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/emailGeneva on AWS EKS
Geneva can be used to provision Ray clusters running in Amazon Web Services (AWS) Elastic Kubernetes Service (EKS).
In the following sections we’ll use these variables:
NAMESPACE=geneva # replace with your actual namespace if different
CLUSTER=geneva # replace with your actual namespace if different
KSA_NAME=geneva-ray-runner # replace with an identity nameEKS Node Groups
EKS allows you to specify templates for virtual machines in “node groups”. These allow you to manage and configure resources such as the number of CPUs, number of GPUs, amount of memory, and if instances are spot or regular virtual machines.
You can define your node groups however you want but Geneva uses three specific Kubernetes labels when deploying Ray pods on EKS: ray-head, ray-worker-cpu, ray-worker-gpu
-
Head nodes are where the Ray dashboard and scheduler run. They should be non-spot instances and should not have processing workloads scheduled on them. Geneva looks for nodes with the
geneva.lancedb.com/ray-head: truek8s label for this role. -
CPU Worker nodes are where distributed processing that does not require GPU should be scheduled. Geneva looks for nodes with the
geneva.lancedb.com/ray-worker-cpu: truek8s label when these nodes are requested. -
GPU Worker nodes are where distributed processing that require GPU should be scheduled. Geneva looks for nodes with the
geneva.lancedb.com/ray-worker-gpu: truek8s label when these nodes are requested.
Install KubeRay Operator Using Helm
Geneva requires the KubeRay operator to be installed in your EKS cluster.
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
helm repo update
helm install kuberay-operator kuberay/kuberay-operator -n $NAMESPACEInstall NVIDIA Device Plugin
For GPU support, the NVIDIA device plugin must be installed in your EKS cluster:
curl https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.0/deployments/static/nvidia-device-plugin.yml > nvidia-device-plugin.yml
kubectl apply -f nvidia-device-plugin.ymlConfigure Access Control
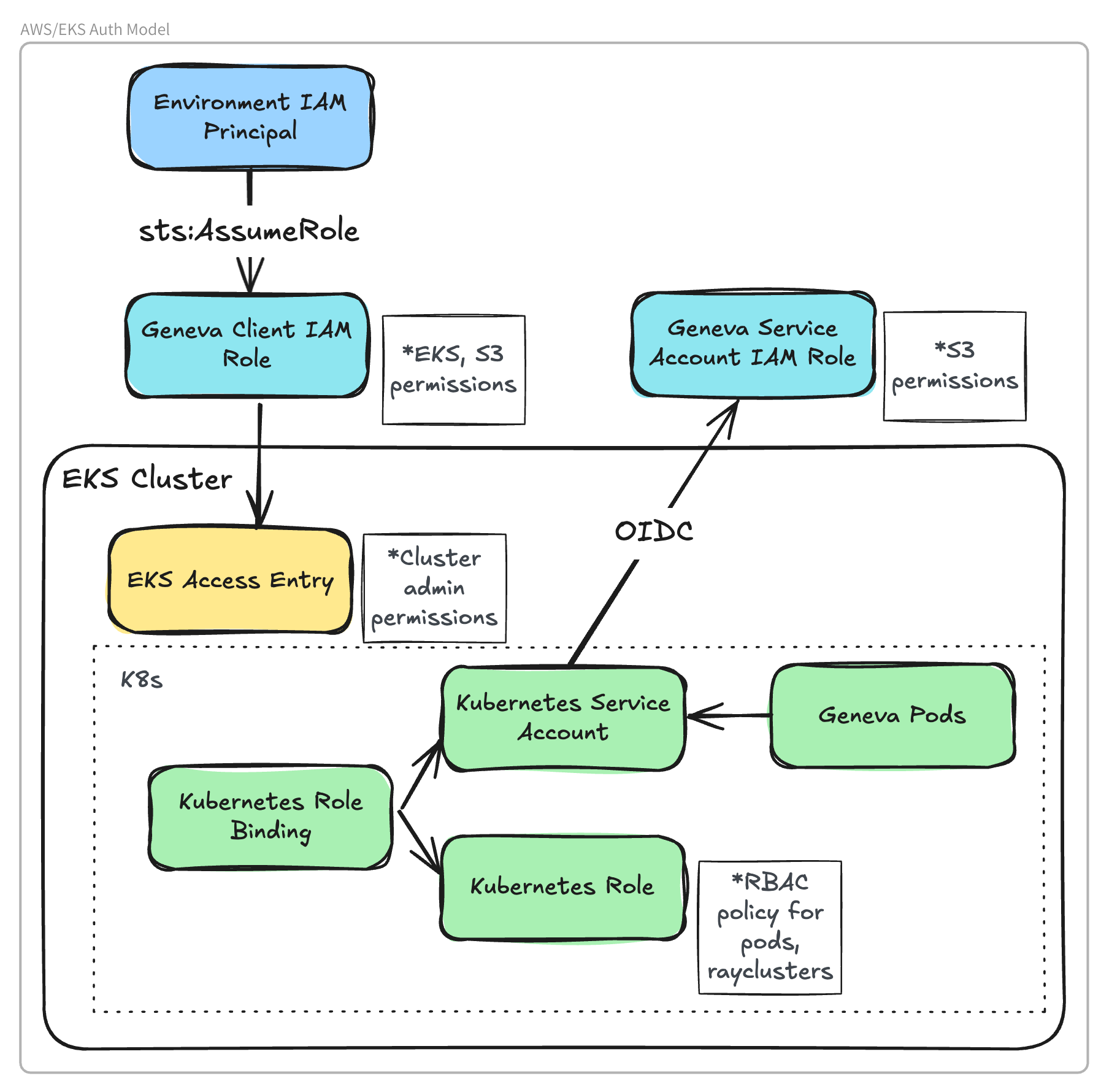
Environment IAM Principal
Geneva must be run in an environment with access to
AWS credentials
with permissions to sts:AssumeRole on the Geneva Client IAM Role.
For example, this could be a laptop with credentials provided by environment variables, or an EC2 instance with credentials provided via Instance Profile.
Create IAM Role for Geneva Client
The Geneva Client IAM Role is assumed by the Geneva client to provision the Kuberay cluster and run remote jobs.
This role requires IAM permissions to access the storage bucket and Kubernetes API.
Create an IAM role with the following policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ClusterAccess",
"Action": [
"eks:DescribeCluster",
"eks:AccessKubernetesApi"
],
"Effect": "Allow",
"Resource": "<your eks cluster arn>"
},
{
"Sid": "AllowListBucket",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::<your storage bucket>"
},
{
"Sid": "AllowAllS3ObjectActions",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:HeadObject"
],
"Resource": "arn:aws:s3:::<your storage bucket>/*"
}
]
}This role should also have a trust policy with sts:AssumeRole permissions for any principal initiating the Geneva client.
When using Geneva, this role can be specified with the role_name RayCluster parameter.
Create EKS Access Entry
Create an EKS access entry to allow the Geneva Client Role to access the Kubernetes API for the EKS Cluster.
aws eks create-access-entry --cluster-name $CLUSTER --principal-arn <your geneva client role ARN> --type STANDARD
aws eks associate-access-policy --cluster-name $CLUSTER --principal-arn <your geneva client role ARN> --access-scope type=cluster --policy-arn arn:aws:eks::aws:cluster-access-policy/AmazonEKSClusterAdminPolicyCreate EKS OIDC Provider
Create an OIDC provider for your EKS cluster. This is required to allow Kubernetes Service Accounts (KSA) to assume IAM roles. See AWS documentation .
Create IAM Role for Service Account
An IAM role is required for the Kubernetes Service Account (KSA) that will be used by the Ray head and worker pods.
This role must have permissions to access the storage bucket and to describe the EKS cluster:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ClusterAccess",
"Action": [
"eks:DescribeCluster"
],
"Effect": "Allow",
"Resource": "<your eks cluster arn>"
},
{
"Sid": "AllowListBucket",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::<your storage bucket>"
},
{
"Sid": "AllowAllS3ObjectActions",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:HeadObject"
],
"Resource": "arn:aws:s3:::<your storage bucket>/*"
}
]
}In addition, it must have a trust policy allowing the EKS OIDC provider to assume the role from the Kubernetes Service Account:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "<OIDC Provider ARN>"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"<OIDC Provider>:aud": "sts.amazonaws.com",
"<OIDC Provider>:sub": "system:serviceaccount:$NAMESPACE:$KSA_NAME"
}
}
}
]
}Associate the IAM Role with the Kubernetes Service Account
Modify the Kubernetes Service Account created in “Basic Kubernetes setup” to associate it with the IAM role created above.
The role ARN is specified using eks.amazonaws.com/role-arn annotation:
kubectl annotate serviceaccount "$KSA_NAME" \
-n "$NAMESPACE" \
"eks.amazonaws.com/role-arn=$ROLE_ARN" \
--overwriteInitialize the Ray Cluster
Initialize the Ray cluster using the node selectors and metadata from above:
from geneva.runners.ray._mgr import ray_cluster
from geneva.runners.ray.raycluster import (K8sConfigMethod, _HeadGroupSpec, _WorkerGroupSpec)
head_spec = _HeadGroupSpec(
service_account="geneva-ray-runner",
num_cpus=1,
memory=2048,
node_selector={"geneva.lancedb.com/ray-head": "true"},
)
worker_spec = _WorkerGroupSpec(
name="worker",
min_replicas=1,
service_account="geneva-ray-runner",
num_cpus=2,
memory=4096,
node_selector={"geneva.lancedb.com/ray-worker-cpu": "true"},
)
with ray_cluster(
name="my-ray-cluster",
namespace="geneva",
cluster_name="geneva",
config_method=K8sConfigMethod.EKS_AUTH,
region="us-east-1",
use_portforwarding=True,
head_group=head_spec,
worker_groups=[worker_spec],
role_name="geneva-client-role",
) as cluster:
table.backfill("embedding")