LanceDB is a multimodal lakehouse that serves two different use cases, both built on the foundation of the powerful Lance format .
Vector Search and Generative AI LanceDB can be used as a vector database to build production-ready AI applications. Vector search is available in OSS , Cloud , and Enterprise editions.
Training, Feature Engineering and Analytics Our enterprise-grade platform enables ML engineers and data scientists to perform large-scale training, multimodal EDA and AI model experimentation. Lakehouse features are available in OSS and Enterprise editions.
LanceDB is the preferred choice for developers building production-ready search and generative AI applications, including e-commerce search, recommendation systems, RAG (Retrieval-Augmented Generation), and autonomous agents.
Acting as a vector database, LanceDB natively stores vectors alongside multiple data modalities (text, images, video, audio), serving as a unified data store that eliminates the need for separate databases to manage source data.
| Feature | LanceDB OSS | LanceDB Cloud | LanceDB Enterprise |
|---|---|---|---|
| Search | ✅ Local | ✅ Managed | ✅ Managed |
| Storage | ✅ Local Disk + AWS S3, Azure Blob, GCS | ✅ Managed | ✅ Managed, with Caching |
| SQL | ✅ Local, via DuckDB, Spark, Trino | ✅ Managed | ✅ Managed |
Our multimodal lakehouse platform empowers ML engineers and data scientists to train and fine-tune custom models on petabyte-scale multimodal datasets.
The platform serves as a unified data hub for internal search, analytics, and model experimentation workflows. Enhanced with SQL analytics, training pipelines, and feature engineering capabilities to accelerate AI development.
| Feature | LanceDB OSS | LanceDB Enterprise |
|---|---|---|
| Search | ✅ Local | ✅ Managed |
| Storage | ✅ Local Disk + AWS S3, Azure Blob, GCS | ✅ Managed, with Caching |
| SQL | ✅ Local, via DuckDB, Spark, Trino | ✅ Managed |
| Training | ✅ Local, via PyTorch | ✅ Managed, via PyTorch |
| Feature Engineering | ✅ API-only (local compute, no caching) | ✅ Managed, via Geneva |
LanceDB is used as a vector database that’s designed to store and search data of different modalities. You can use LanceDB to build fast, scalable, and intelligent applications that rely on vector search and analytics.
It is ideal for powering semantic search engines , recommendation systems , and AI-driven applications (RAG, Agents) that require real-time insights.
The Source of Truth: Most existing vector databases only store and search embeddings and their metadata. The original data is usually stored elsewhere, so you need another database as a source of truth. LanceDB can effortlessly store both the source data and its embeddings.
Technology: It is built on top of Lance , an open-source columnar data format designed for extreme storage, performant ML workloads and fast random access.
Indexing: By combining columnar storage with cutting-edge indexing techniques, LanceDB enables efficient querying of both structured and unstructured data.
Search-at-Scale: Columnar storage for read and write performance on large scale datasets, especially vector-heavy workloads.
Embedded: LanceDB OSS database is a library that runs in-process in your app, making it simple and cheap to implement on top of multiple remote storage options (such as S3).
Serverless: LanceDB Cloud is a fully managed, serverless vector database that scales automatically with your storage or search needs, eliminating infrastructure management overhead.
Managed: LanceDB Enterprise offers a dedicated, enterprise-grade deployment with advanced security, compliance features, and dedicated support for mission-critical AI applications.
Scalability: Optimized for performance at scale, the Enterprise edition supports a fully managed, horizontally scalable deployment that can handle billions of rows and petabyte-scale data volumes.
Caching for Performance: A distributed NVMe cache fleet enables high IOPS and throughput—up to 5M IOPS and 10+ GB/s—while reducing API calls to cloud object stores like S3, GCS, and Azure Blob. This dramatically lowers inference and training costs.
Resilience: Feature engineering pipelines include built-in checkpointing and automatic resumption, making workloads resilient to interruptions and suitable for preemptible (spot) instances.
Distributed Processing: Python user-defined functions (UDFs) orchestrate distributed data transformations across Ray or Kubernetes clusters, allowing fast, declarative feature creation and evolution.
ML Workflow Integration: Offers fast random access, named SQL views for training, and direct integration with PyTorch/JAX data loaders to streamline ML workflows.
Enterprise Security: Supports BYOC (Bring Your Own Cloud), integrating natively with cloud provider security (IAM, audit logs, encryption) and enables private connectivity via AWS PrivateLink or GCP Private Service Connect.
Production Ready: Includes telemetry pipelines, enterprise SLAs, and control plane integration for job scheduling and observability across training, analytics, and search.
LanceDB integrates seamlessly with the modern AI ecosystem, providing connectors for popular frameworks, embedding models, and development tools. Read more about LanceDB Integrations.
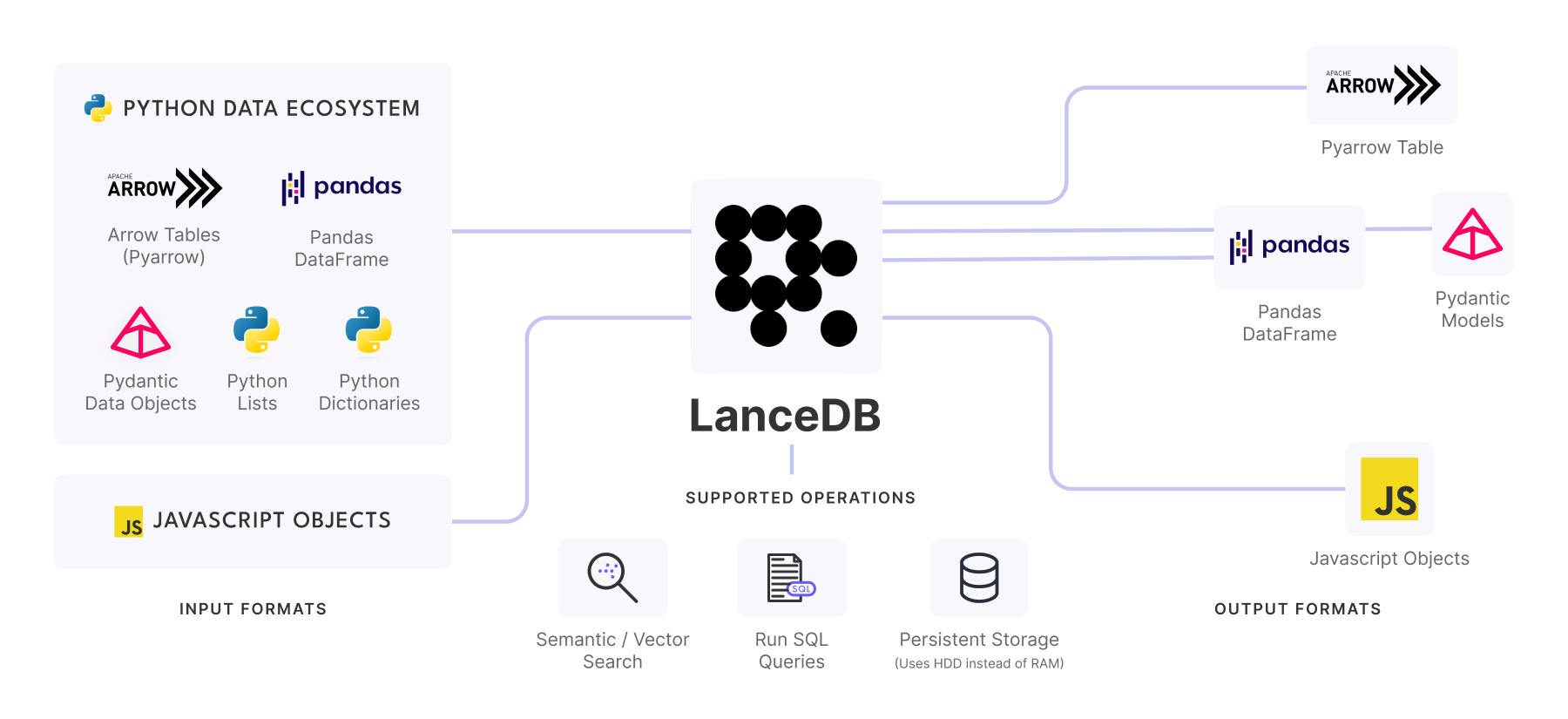
| Category | Integrations | Documentation |
|---|---|---|
| AI Frameworks | LangChain, LlamaIndex, Kiln | AI Frameworks |
| Embedding Models | OpenAI, Cohere, Hugging Face, Custom Models | Embedding Models |
| Reranking Models | BGE-reranker, Cohere Rerank, Custom Models | Reranking Models |
| Data Platforms | DuckDB, Pandas, Polars | Data Platforms |
Create a LanceDB Cloud account to get started in minutes! Follow our guided tutorials to: