

As multimodal AI progresses, systems are being pushed to handle far more than scalar data – images, audio, video, PDFs, and more. These binary large objects (blobs) are no longer occasional appendages; they now sit at the center of everyday workloads.
Yet if you examine how existing systems are designed, an awkward reality emerges: multimodal data is still not treated as a first-class citizen. Blobs are neither like numbers, which fit naturally into columns, nor like strings, which can make do almost anywhere. In practice, blobs are pushed into external storage, managed through separate systems, and stitched back together with application-layer glue code. The result is fragmented governance, operational complexity, and a constant tension between performance and manageability.
Lance Blob V2 changes this. This post tells the story of our journey – from understanding the fundamental problems, through our first iteration with Lance Blob V1, to designing what we believe makes multimodal data a first-class citizen in the lakehouse.
Three Real-World Problems for Blobs
At LanceDB, we work closely with frontier AI labs – Runway, Midjourney, WorldLabs, Harvey, and many others – to make multimodal data easy to consume through the Lance format and the LanceDB multimodal lakehouse. Based on our interactions with these customers and the broader open source community, we’ve identified three genuine pain points that consistently appear in production environments. No matter which clever method you use to handle blobs, you eventually hit these walls.
Problem 1: Mixed Blob Access Strategy
Mixing small and large objects in the same column – a single strategy is inherently unstable.
A very common pattern in multimodal datasets is a long-tail distribution: a large number of small objects (tens of KB), mixed with a few large objects ranging from MBs to hundreds of GBs.
- Small objects need locality and low overhead: they shouldn’t slow down full table scans, and random reads shouldn’t take detours.
- Large objects need operability: they shouldn’t be rewritten unnecessarily; ideally, they can be cached, migrated, and governed independently, preventing a table-level compaction from turning into a massive I/O nightmare.
Trying to serve both types of objects with one physical storage strategy often results in a system that’s “fine most of the time, but suddenly terrible with certain batches.” In production systems, that kind of surprise is rarely welcome.
Problem 2: Existing External Reference
Many blobs already live in object storage – “reference, don’t copy” is a hard requirement.
Many teams already have mature media asset libraries: established path structures, permission systems, hot/cold tiering, and lifecycle policies. In such cases, copying the content into the table often isn’t a benefit; it’s duplicated cost and fragmented governance.
More critically, reading isn’t always about reading the whole object. Common access patterns for video, audio, and large binaries are: I only need this specific range. If the system doesn’t natively incorporate the semantics of external reference + range read into its core capabilities, users are left doing complex stitching in the application layer – half business logic, half storage system patches, leaving no one with an easy job.
Problem 3: Lifecycle Governance
When data lives outside the table, governance must be handled by the system.
For performance and cost reasons, systems often use external blob sidecars (such as packed files and dedicated object files). The real difficulty lies in subsequent governance: which objects are still referenced by a dataset version? Which have become orphans eligible for garbage collection? How do you safely clean up under snapshots and version evolution?
If users have to maintain manifests, write scripts for reconciliation, or stay up at night monitoring garbage collection results, then blobs will forever remain supporting characters, and the system can’t provide a consistent operational experience.
These problems aren’t unique to Lance, but since we encountered them, we aimed to solve them fundamentally, not with patches.
Existing Approaches
Before diving into our latest blob support, let’s examine the two common approaches we’ve seen for handling blob storage. Understanding why each approach hits the three problems outlined above will clarify why we believe these are fundamental walls – not just implementation gaps that can be patched over.
Approach 1: Everything as an External Reference
This is what most formats today do. There are two main reasons for this design choice:
- Simplicity through uniformity. Since reference, don’t copy is a hard requirement in many cases, why not make everything an external reference to keep things simple? With object storage offering virtually infinite capacity, the natural solution is to store multimodal data as separate files and record pointers in the table.
- Format limitations. OLAP-centric columnar file formats are fundamentally inefficient at storing blobs inline because of their row group-based layout. A row group is either too large (making writes slow and reads inefficient when you only need a few images) or too small (creating excessive metadata overhead and poor compression). Storing blobs as external references plays to what these formats do well – storing path strings efficiently – while avoiding what they struggle with.
This approach has become so prevalent that modern lakehouse stacks have built dedicated abstractions around it. Unity Catalog offers Volumes , Apache Gravitino provides Filesets – dedicated endpoints and concepts that appear to elevate blobs to first-class status. But look closer: these abstractions are still separate from tables, governed through different APIs, and managed as a segregated component in the catalog. They’re adding a governance layer on top of the same fundamental approach – blobs live outside your data, and you’re responsible for keeping the two in sync.
Circling back to the three problems we listed above, making everything an external reference solves Problem 2: Existing External Reference completely. However, this approach creates issues with the other two:
Inefficiency in Multimodal AI Training
This hits Problem 1: Mixed Blob Access Strategy head-on. Model training typically constrains multimodal data sizes to under 1MB for images and under 5MB for video clips. These small blobs need locality and low overhead – exactly what external references fail to provide. Two performance problems dominate:
- GPU Utilization. Pulling billions of images and video clips into GPU memory during training wastes precious GPU cycles. With the external reference approach, training typically becomes I/O bound due to object store connection overhead. Each blob requires a separate HTTP request, and the latency adds up quickly at scale.
- Storage Metadata Bottleneck. For some object stores – and especially high-performance file systems used for training – too many files create metadata pressure. Having billions of references means billions of objects, which makes storage access inherently slow.
Data Lifecycle Management Pains
Here we encounter Problem 3: Lifecycle Governance . External references don’t follow the same lifecycle as rows. You can delete a row, but the image or video clip it pointed to is still left behind. Complicated pipelines and large joins across tables have to be implemented just to track which blobs are still referenced. The transactional properties of a table format – ACID guarantees, time travel, consistent snapshots – no longer apply when you need to ensure your image set is compliant with requirements like GDPR.
Approach 2: Everything Stored Inline
As an AI-native format, Lance was designed with the problems AI researchers encountered when using external references. This motivated the original development of Lance Blob encoding (Lance Blob V1). We addressed these problems by storing blobs directly inline with an optimized encoding strategy. The Lance file format doesn’t have row groups, so it avoids the constraints that row groups impose on multimodal data. Our specialized blob encoding stores blob bytes out-of-band: the pages in Lance only contain blob metadata (starting position and size), while actual blob bytes are stored outside the page structure. This keeps pages compact while making blobs continuously addressable.
Here’s what writing and reading blobs looks like with the Lance Blob API:
import lance
import pyarrow as pa
# Write blobs to a Lance dataset
values = pa.array([b"image_bytes_1", b"image_bytes_2", b"image_bytes_3"], pa.large_binary())
table = pa.table(
[values, pa.array([0, 1, 2])],
schema=pa.schema([
pa.field("image", pa.large_binary(), metadata={"lance-encoding:blob": "true"}),
pa.field("id", pa.uint64()),
])
)
ds = lance.write_dataset(table, "/tmp/images.lance")
# Read blobs back using the blob API
blobs = ds.take_blobs("image", indices=[0, 1, 2])
for blob in blobs:
with blob as f:
data = f.read() # File-like interface with seek supportThis approach addresses the training inefficiency problem , delivering high performance in GPU-based training since blobs are co-located with other metadata when brought into GPU memory. It also minimizes the number of files in storage, avoiding the metadata overhead that plagues the pointer approach. And blobs (e.g., images) follow the same lifecycle as rows – delete a row, and the blob is cleaned up atomically.
However, circling back to the three problems listed above, Lance Blob V1 encounters the following limitations:
The Big File Problem
With Lance’s data evolution feature, which makes it easy to add new columns, users want to store very large raw multimodal data in Lance – high-resolution images, entire videos, and large documents – and then iteratively add features, embeddings, and downsized samples as new columns.
Although users can still read data efficiently because of Lance’s columnar layout, the data files become so large that meaningful size-based compaction becomes difficult. A few rows can already produce a file several GB in size. Even worse, each compaction would rewrite the source blobs – an expensive operation that’s never actually necessary since the raw data rarely changes. This is Problem 1: Mixed Blob Access Strategy from a different angle.
Migration Blocker
This circles back to Problem 2: Existing External Reference , but from the opposite direction. Even if an organization wants to adopt Lance blob encoding, migration is often blocked by established upstream workflows. Many teams have ingestion pipelines that simply dump multimodal data into object storage buckets – a pattern that’s been working for years. These organizations want the benefits of Lance’s blob lifecycle governance, but they can’t realistically rewrite their entire ingestion infrastructure overnight. What they need is a gradual migration path: the ability to reference existing external blobs while incrementally moving data into Lance, living in a hybrid state during the transition. Lance Blob V1’s all-or-nothing inline approach doesn’t support this.
Some Self-Reflections
Lance Blob V1 treated blobs as a kind of access technique: storing bytes out-of-band within a file and locating them via offsets. It’s simple, low-cost, covers many scenarios, and serves the AI training use case extremely well. But it implies a fundamental premise: there’s essentially only one physical manifestation of a blob.
When workloads enter the mixed size + mixed source + mixed access pattern phase, the bottleneck shifts from the implementation level to the semantic level: the system cannot clearly express what this blob is and how it should be treated. Insufficient semantic expression directly limits optimization potential and pushes complexity to the user side – ultimately, users end up compensating for the system’s lack of abstraction.
So, one of the key changes in our redesign is elevating blobs from an ancillary technique to a system-level data asset. This means the system takes responsibility for blobs, rather than just treating them as bags of bytes.
Introducing Lance Blob V2
Existing systems treat blobs as second-class citizens – something to be managed outside the table, governed separately, accessed through workarounds. Lance Blob V2 takes the opposite approach: blobs belong inside the system, with the same level of care as any other column type.
Making this real starts with clarifying the division of labor:
- What users need to express is actually quite limited: either provide the content (bytes), or provide the location (external URI), and optionally state, I only care about this specific range.
- What the system needs to handle is much broader: decide on the storage method, how to locate and read data, how to govern the lifecycle during version evolution, and try not to leak these decisions into the user interface.
The core design of Lance Blob V2 is to decouple user expression from system storage. The upper layer maintains simple, stable expressions, while the underlying layer has clear, deterministic storage semantics. This allows the system to evolve continuously without disrupting the user’s mental model – supporting a few layouts today, with room for more optimization strategies in the future, without requiring users to rewrite their business logic.
Here’s a little behind-the-scenes secret: initially, we tried to create a universal layout, attempting to cover all scenarios with one strategy. We quickly found it was impossible. We had to accept reality: there is no single layout that’s best for all blobs. So, we shifted to multi-semantic storage.
Lance Blob V2 Storage Semantics
Lance Blob V2 introduces multiple storage semantics, allowing different objects within the same column to choose the most suitable home based on their characteristics – the system acknowledges differences and allows selection based on workload needs. Each semantic corresponds to a physical layout, but what users see is always a unified blob type.
Inline: Small objects treated like regular values
Suitable for small objects (up to 64 KB by default), stored directly within the main data file. Emphasizes locality, low metadata overhead, and a simple read path. Small blobs don’t need to pay the complexity tax of the large-object world. A practical example: if your dataset mostly contains thumbnails, they will be stored inline and returned alongside the row data during reads, with zero additional overhead.
Packed: Medium objects balance throughput and cost via batching
Suitable for numerous, medium-sized objects (64 KB to 4 MB by default), like mid-sized images or audio clips. They are packed into shared .blob sidecar files (up to 1 GiB each). This prevents the main data file from being constantly bloated and rewritten by blobs, and avoids the management pressure of each object being its own file. During execution, Lance automatically aggregates data into the same file based on configured thresholds and actively splits files at appropriate points to ensure each pack file is reasonably sized. This maintains batch read throughput while controlling the cost of random access.
Dedicated: Large objects gain operability as independent assets
Suitable for truly large objects (over 4 MB by default), like HD videos or complete PDFs. They are stored as individual .blob files, isolated from the table-level rewrite/compaction path, making migration, caching, and lifecycle policies much more controllable. This aligns with common sense: big items should be handled separately. When a user performs a range read on a large file, the system can directly leverage the object store’s native range read capability, avoiding loading the entire file.
External: External asset references as a first-class path
Suitable for assets already residing in object storage or media libraries. The blob column stores only the URI; during reads, the system transparently redirects to external storage. Emphasizes interoperability, avoids copying, and naturally supports access patterns like range reads.
What makes Lance external blobs even more powerful is their integration with Lance’s multi-base layout . When an external URI maps to a registered base path, Lance stores only the relative path and base ID – keeping the descriptor compact while enabling full lifecycle management. URIs outside registered bases are rejected by default; users must explicitly opt in to store absolute external URIs, acknowledging that lifecycle management for these objects remains their responsibility.
The key point here is that the system integrates four modes into a single semantic framework, making mixed workloads within a column the norm, not the exception. When writing data, users only need to provide the blob content or URI; the system automatically selects the appropriate storage semantics based on blob size and configuration.
Lance Blob V2 Format Design
What makes Lance Blob V2 possible is the seamless integration between the Lance file format and table format. Unlike systems where file and table formats are developed separately (e.g., Parquet + Iceberg), Lance controls both layers. This allows us to extend blob support from the file level into the table level, enabling seamless routing across all four storage semantics without exposing complexity to users.
Unified Blob Type Representation in File Format
At the core of Lance Blob V2 is a unified type representation. Regardless of where a blob is physically stored, the on-disk descriptor is always the same Arrow struct:
This uniform representation is the key to a unified read API. The reader examines the kind field to determine the storage type, then uses the appropriate fields to locate and read the blob data.
Thresholds for Different Storage Semantics
Lance Blob V2 automatically selects the storage semantic based on blob size:
These thresholds are configurable via schema metadata, but the defaults are tuned for typical multimodal AI workloads.
File and Table Format Integration
The Lance file format and table format work together to manage blobs across all storage semantics. Here's how the pieces fit together:
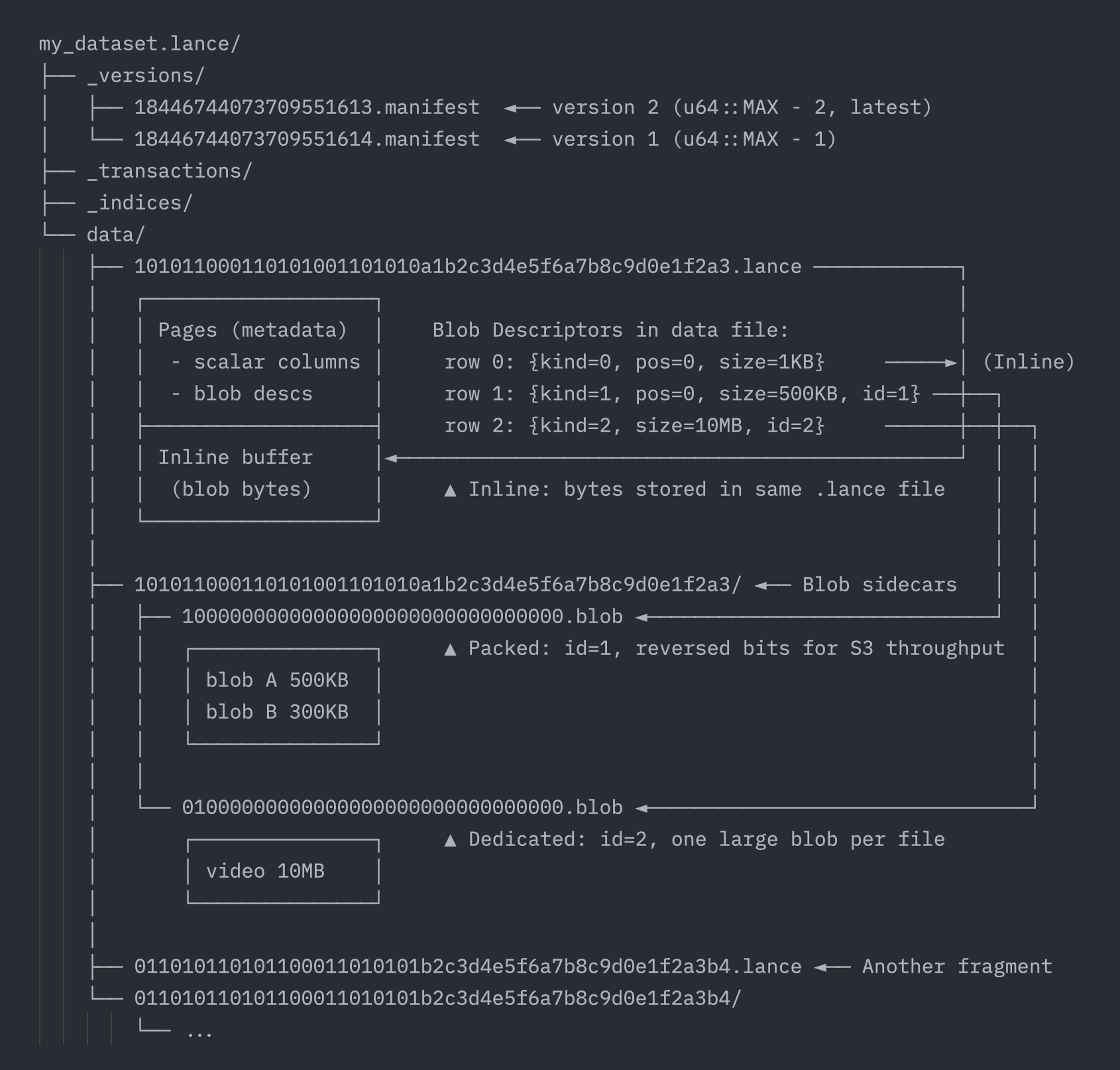
For Inline blobs (≤ 64 KB), the file format handles everything. The data file stores position/size metadata in pages, while actual blob bytes are written to a dedicated buffer section within the same .lance file − keeping pages compact while maintaining locality.
For Packed and Dedicated blobs, the table format takes over:
- Packed files (
.blobsidecars) batch multiple medium-sized blobs into shared files up to 1 GiB each, reducing file count. - Dedicated files store one blob per file, enabling direct range reads via object storage APIs and isolating large blobs from compaction.
The table format coordinates lifecycle through fragment metadata:
This enables efficient path encoding (4-byte blob_id instead of full URIs), lifecycle tracking (safe garbage collection), and repack operations (consolidate sparse packs without rewriting data files).
💡 Note on file naming
You might be curious about all these010101...prefixes. Lance uses various techniques to maximize object storage throughput − for example, blob file names use the reversed binary string of the blob ID. How Lance optimizes file naming across manifests, data files, and blob sidecars deserves its own dedicated blog post. Stay tuned!
A Unified Experience for Blobs
In systems where blobs are second-class citizens, users must know where the data lives and how it was stored − then write different code paths accordingly. First-class citizenship means the opposite: users shouldn't need to change their reading methods just because the physical layout changes.
Lance Blob V2 achieves this by keeping the read experience uniform across all storage semantics. Users can reliably build applications around a stable abstraction, without baking details like where the data is actually stored into their business logic. More intuitively: you get a readable blob. Whether it originates from a data file, a packed carrier, a dedicated object file, or an external URI − the system determines that and handles it transparently.
The Lance blob API − take_blobs(), BlobFile.read(), BlobFile.seek() − works identically across all four storage semantics: Inline, Packed, Dedicated, and External. The same file-like interface lets you read bytes, seek to offsets, and stream ranges, regardless of whether the blob lives in the main data file, a shared pack file, a dedicated object, or an external URI. Behind the scenes, the system examines the kind field in the blob descriptor and dynamically routes to the correct read path. If we introduce new storage layouts in the future, user code remains unchanged.
import lance
import pyarrow as pa
from lance import Blob
# 1) Build mixed blob values -- each ends up in a different storage semantic
small_bytes = b"tiny-inline-data" # → Inline (≤64 KB)
medium_bytes = b"x" * 100_000 # → Packed (64 KB - 4 MB)
large_bytes = b"y" * 5_000_000 # → Dedicated (> 4 MB)
external_uri = "/path/to/existing/video.mp4" # → External (URI reference)
values = [
small_bytes,
medium_bytes,
large_bytes,
external_uri,
Blob.from_uri(external_uri, position=1024, size=4096), # External range slice
]
# 2) Build table using blob extension array
table = pa.table({
"id": pa.array([1, 2, 3, 4, 5]),
"blob": lance.blob_array(values),
})
# 3) Write with blob v2-enabled storage version
ds = lance.write_dataset(table, "./blob_v2_demo.lance", data_storage_version="2.2")
# 4) Inspect schema -- blob column uses lance.blob.v2 extension type
print(ds.schema)
# id: int64
# blob: extension<lance.blob.v2<...>>
# 5) Read descriptors to see storage semantics
# kind field: 0=Inline, 1=Packed, 2=Dedicated, 3=External
descriptors = ds.to_table(columns=["blob"]).column("blob")
for i, desc in enumerate(descriptors):
d = desc.as_py()
kind_name = ["Inline", "Packed", "Dedicated", "External"][d["kind"]]
print(f"Row {i}: {kind_name} (size={d['size']})")
# Row 0: Inline (size=16)
# Row 1: Packed (size=100000)
# Row 2: Dedicated (size=5000000)
# Row 3: External (size=...)
# Row 4: External (size=4096)
# 6) Read via unified blob API -- same interface for ALL storage semantics
blobs = ds.take_blobs("blob", indices=[0, 1, 2])
for blob in blobs:
with blob as f:
data = f.read() # Works identically for Inline, Packed, Dedicated, and External
f.seek(0) # Seek support across all storage typesA Fully Governed Experience for Blobs
Multi-semantic storage introduces a hard requirement: the system must be able to safely reclaim and govern data that lives outside the table, otherwise it creates new operational minefields. Lance Blob V2 places governability on par with performance. It enables the system to determine reachability within the context of dataset versions and snapshots, safely identifying and reclaiming orphaned carriers without requiring users to maintain extra manifests.
Consider this example where a dataset evolves through multiple versions:
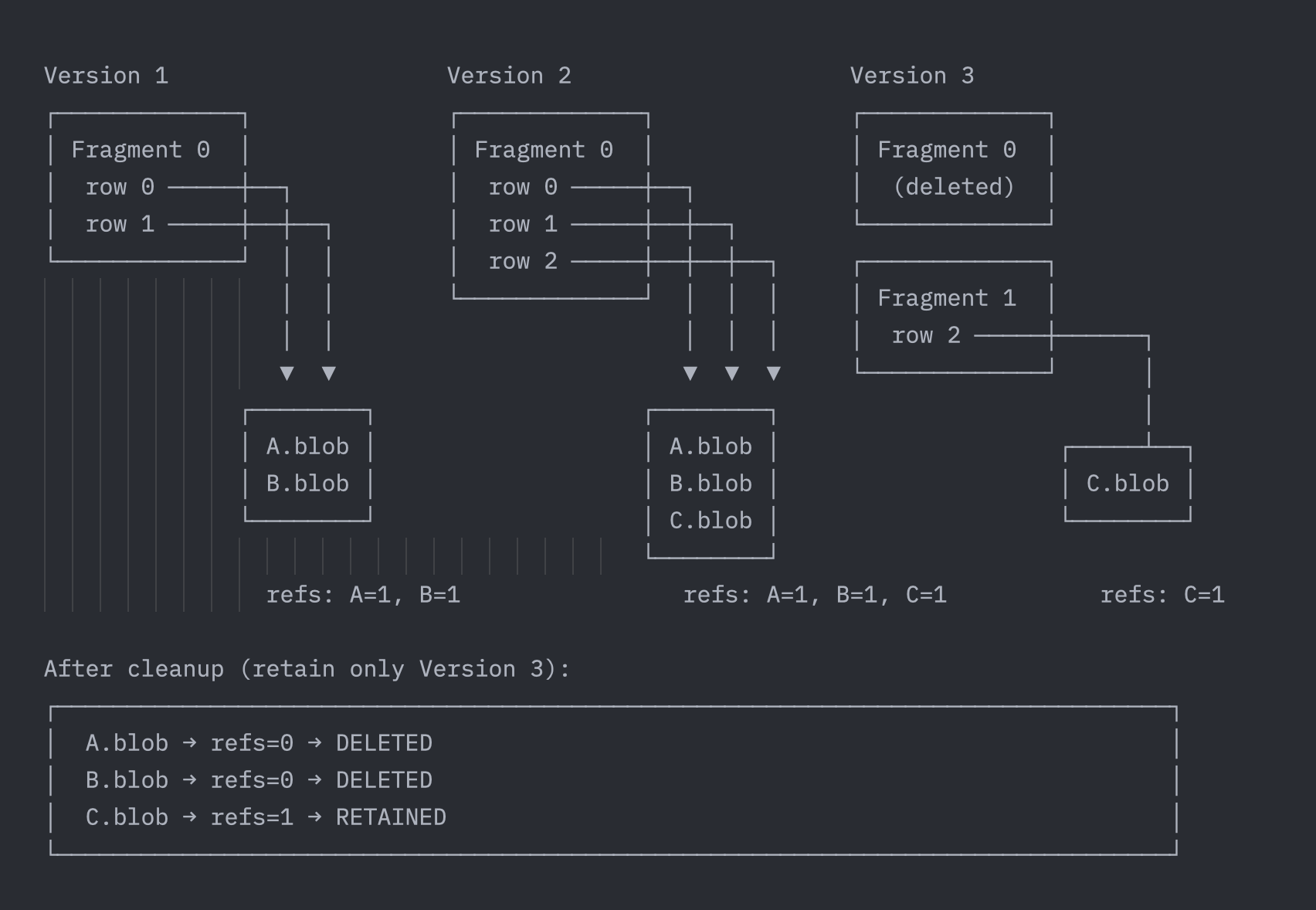
When a dataset undergoes version cleanup, the system scans all external blob objects, retaining only those objects still referenced by active versions. Blobs A.blob and B.blob were only referenced by Versions 1 and 2 − once those versions are cleaned up, the blobs become orphans and are safely garbage collected. This process is automatic, incremental, and non-blocking for normal reads and writes.This reflects a shift in attitude: blobs are part of the dataset and should be treated equally during version evolution, cleanup, and migration − not considered "done" once written out.
This experience extends to external blobs as well. Since external blob bases are tracked in the manifest, the system can determine reachability for external objects just like managed sidecars. They get automatic garbage collection, and compute engines can apply credentials vending and column-level policies just as they would for any other table and column. No more separate Volumes and Filesets − your multimodal data gets the same management and governance as the rest of your tabular data.
Conclusions
For too long, multimodal data has been relegated to external storage, managed via separate systems, and stitched together with application-layer workarounds. Lance Blob V2 changes this by treating blobs with the same rigor as any other column type. Whether it's images, audio, video, or raw samples, you can manipulate them just like regular columns, while benefiting from efficient system-level layouts and automatic governance.
This means you can:
- Use Inline storage for massive amounts of small samples (e.g., image thumbnails, audio clips). Reads return data directly with the row, requiring no extra I/O, significantly boosting training data loading efficiency.
- Use Packed to manage medium-sized multimodal objects (e.g., mid-sized images, embedding files). The system automatically batches them into shared
.blobsidecar files, balancing throughput and cost while avoiding file count explosion. - Use Dedicated to isolate large files (e.g., HD videos, complete PDFs). They live in individual
.blobfiles independently of table compaction paths, simplifying caching, migration, and lifecycle management, while range reads leverage underlying optimizations directly. - Use External to seamlessly integrate with existing media asset libraries (e.g., video datasets in object storage). Store only URIs without copying content, natively support range reads, and keep your business logic independent of storage locations.
- Use the unified blob API to shield all physical layout differences.
take_blobs(),read(), andseek()work identically across all four storage semantics − storage strategies can evolve internally while your data processing code remains unchanged. - Let the system automatically govern external blob objects. No need for manual cleanup scripts during version evolution or separate access-control mechanisms, ensuring cost control, data integrity, and security.
Circling back to the three problems we started with: Lance Blob V2 addresses mixed blob access strategies by letting different storage semantics coexist within a single column. It solves external reference migration by treating URIs as first-class blob values alongside inline bytes. And it handles lifecycle governance through version-aware reference counting that automatically garbage collects orphaned blobs.
The seamless integration between Lance's file format and table format makes this possible. Blob sidecar files live alongside data files in a predictable structure, tracked through fragment metadata, and cleaned up through the same version evolution mechanisms that govern the rest of the dataset.
With these foundational capabilities, we see a clearer path forward: future versions of Lance can manage multimodal data with the same ease that Git manages code − branches, tags, snapshots, fine-grained permissions − all built on top of an open format. This lets ML/AI teams focus on their models and experiments, rather than the complexities of the data pipeline.
Multimodal data deserves better than second-class treatment. With Lance Blob V2, it finally gets it.




